Data Science 511
Welcome to Data Science 511! This course is an introduction to the tools and practices of data scientists. Our goal is to get you familiar with how work is done in data science, at an individual level as well as in collaborative settings. This is an interdisciplinary field that includes people from all sorts of backgrounds and experience, but there are things that all data scientists share. This course will give you experience in working as a data scientist, and will point you to tools that you can use, regardless of where your research interests take you.
We will begin with work at an individual level, getting familiar with the tools that each data scientist can use when working on a solo project. Gradually, we will expand our approach to show how those same tools can be used to collaborate with other individuals, teams, and large organizations. As we go through the semester, we will find how each of these tools benefit us, and how they can be combined in powerful ways.
As we said before, data scientists come from all sorts of backgrounds. This diversity is a strength of data science and often leads to interesting projects and perspectives that you may not be familiar with. Don’t be intimidated by not knowing everything. There will always be elements of things that we do not know. Build up experience with the tools at your disposal, and you will find yourself able to collaborate and learn as you go.
Todd Young
Introduction
I am glad that you decided to take this course! I believe the tools that we will introduce will prove invaluable as you develop your own skills as a researcher and data scientist. Many of these tools have been around since the advent of modern computing. They are tried and tested, and they are continue to improve as time goes on. While they can sometimes feel foreign and their interfaces may feel ancient, trust me when I say that there is good reason that they look and feel the way that they do. Don’t be tempted to think that the flashiest tool is the best tool.
This course is actively developed on GitHub using the tools that we will discuss. Don’t worry if some things feel opaque at first. It takes time to get a sense of these tools and ideas. As we go throught the course, things that at first seemed opaque will become clear. Sometimes we have to experience things without fully understanding them, gradually building context and experience as we go. And there will always be more to learn.
Context
I believe it is important to consider this course and data science in context. Data science is a broad term, and many people have many takes on what it means. For some, it is about data preprocessing, visualization, and summarization. For others, it is largely about machine learning models. Some people consider themselves more akin to statisticians or mathematicians, others more closely align with computer scientists.
My opinion, and this is biased for sure, is that data science most closely associated with computer science. Sure, many of the models that we consider are statistical in nature, but the more often than not, the tools data scientists use are squarely in the wheelhouse of computing. If much of the tools that we are using relate to computing, then we ought to pay attention to what computer science gives us. Computer science has long been concerned with managing data and using it effectively. Data science may be a fairly recent term, but many of the ideas in this field have been considered by computer scientists.
One of the great things about PhD work is that you get to plot your own course with your studies. This is especially true with the Bredesen Center as it is intended to be interdisciplinary. So let me encourage you to seek out diverse perspectives across the University of Tennessee and Oak Ridge National Lab. They are both great places to study and do research.
When I studied at UT, I stradled the Math, Statistics, and Computer Science departments. If it is not already clear from above, I hold most strongly to the Computer Science department, but both the Math and Statistics Departments have their strengths. Feel free to ask me questions about my experience at UT. Though I will be biased, I may be able to help orient you as you seek out courses and research during your time at UT. Fair warning, I will likely encourage you to take plenty of computer science courses.
Data Science 511 Syllabus
DSE511 Fall 2020
Meeting Time: MWF 6:00 PM - 6:50 PM
Location: Online - Canvas
Office Hours: online by appointment
Credit Hours: 3
Textbook: None
Prerequisites: None
Course Number: 53690
Instructors:
Jacob Hinkle - hinklejd@ornl.gov
Todd Young - youngmt1@ornl.gov
TA: None
Note: Please include DSE 511 in subject line of emails
Course Description
This course is an introduction to general data science skills not commonly covered in other courses. In particular, we will discuss handling data, best practices for coding, and how to operate in common computing environments like Linux workstations and shared computing clusters. You will learn communication and reproducibility fundamentals to enable your success in large collaborative data science projects.
Assessment and Grading:
Most course-related materials will be posted on Canvas. Your course grade will be evaluated based on your performance in the following areas below. Late assignments will have a 10% penalty per day. If you require extra time to complete an assignment (e.g. due to a paper deadline or other research need), notify the instructors at least one week in advance.
Homework: 30%
Projects: 70%
Individual Project:
We will assign a mid-term project involving ingestion of raw data and basic data analysis. Code and a short report will be produced. Students will be judged on documentation, reproducibility, and functionality of their solution.
Group Project:
We will split the class into groups of 3-5 individuals who will approach a more complex project involving multiple repositories and roles. Students will be expected to work with one another, contribute to each other’s code-bases, and communicate effectively in order to accomplish their task. At the end of the semester a presentation will be prepared by each group, outlining their approach and we will discuss what worked and did not work as a class.The grade system below will be used to determine your final grade. To minimize possible bias, no grades will be rounded and there will be no extra credit.
Grading
The grade system below will be used to determine your final grade. To minimize possible bias, no grades will be rounded and there will be no extra credit.
| Grade | Minimum Percentage |
|---|---|
| A | 90 |
| B | 80 |
| C | 70 |
| D | 60 |
| F | 00 |
Attendance and Participation
Because we will regularly be having group discussions and test material will be presented in class, attendance is expected. No make-up assessments can be scheduled for non-emergency absences. See the university’s policy on valid/excused absences.
Academic Integrity:
“An essential feature of the University of Tennessee, Knoxville is a commitment to maintaining an atmosphere of intellectual integrity and academic honesty. As a student of the university, I pledge that I will neither knowingly give nor receive any inappropriate assistance in academic work, thus affirming my own personal commitment to honor and integrity.” Cheating, plagiarism, or any other type of academic dishonesty will result in a failing grade.
Tentative Class Modules
This schedule is subject to change as we adapt to the experience level of participants.
Introduction
Course introduction/Survey
Software Management with Conda
Environments and dependencies
Intro to text editing
Exploratory Data Analysis & Visualization
Python Data Science Ecosystem
Exploratory Analysis with Notebooks
Introducing Scikit-learn and Pandas
Information Visualization
Scientific Visualization
Interactive Visualization
Machine Learning
Supervised learning
Unsupervised learning
Generalization
Managing randomness
Array Based Computing
Numeric computing in python
Array-based data analysis
Common linear algebra operations
Basic GPU Computing
Data Structures
Variables and namespaces
Functions, closures, and callables
Python classes
Modules and organization
Effective Linux
Introduction to the GNU/Linux command line
Text editors (vim, emacs, others)
Shell scripting and Pipes
Advanced text processing
Data Storage and Access
HDF5 and other common formats
Handling Relational Data
ORM
Basics of graph databases
ETL for graph and relational DBMS
Collaboration
Version control
Collaboration with Github/Gitlab
Project management
Best practices for Python packaging
Testing and CI
Documentation
Typical Data Science Workflows
Computing on Shared Resources
Remote computing with shared computing resources
Containers
HPC
Deep Learning
Multi-node Parallelism
Cloud computing
Supercomputing
Disability Services
Any student who feels s/he may need an accommodation based on the impact of a disability should contact Student Disability Services in Dunford Hall, at 865-974-6087, or by video relay at, 865-622-6566, to coordinate reasonable academic accommodations.
University Civility Statement
Civility is genuine respect and regard for others: politeness, consideration, tact, good manners, graciousness, cordiality, affability, amiability and courteousness. Civility enhances academic freedom and integrity, and is a prerequisite to the free exchange of ideas and knowledge in the learning community. Our community consists of students, faculty, staff, alumni, and campus visitors. Community members affect each other’s well-being and have a shared interest in creating and sustaining an environment where all community members and their points of view are valued and respected. Affirming the value of each member of the university community, the campus asks that all its members adhere to the principles of civility and community adopted by the campus: http://civility.utk.edu/
Your Role in Improving Teaching and Learning Through Course Assessment
At UT, it is our collective responsibility to improve the state of teaching and learning. During the semester, you may be requested to assess aspects of this course either during class or at the completion of the class. You are encouraged to respond to these various forms of assessment as a means of continuing to improve the quality of the UT learning experience.
Key Campus Resources for Students:
Center for Career Development: Career counseling and resources
Hilltopics: Campus and academic policies, procedures and standards of conduct
Student Success Center: Academic support resources
University Libraries: Library resources, databases, course reserves, and services
The instructors reserve the right to revise, alter or amend this syllabus as necessary. Students will be notified of any such changes.
Getting Started with Python
We will be using Python throughout the course. Why Python and not another language like Julia or R? While Julia and R have a lot to bring to the table, Python has been a de facto choice for many data scientists. And for good reason, Python’s ecosystem is mature; there are countless libraries that you can use in your daily work. Inevitably, we will introduce some of these libraries ourselves. Python is also not limited to data analysis. If ever you would like to explore applications outside of data science, Python is not a bad initial choice.
Side Note:
if you are interested other languages, you are in good company. Jacob is a big fan of Haskell and Todd loves Rust and still appreciates C. We can’t include all of the languages we care about in this course, but if you would like to know how you can use another language over the course of your PhD, let us know! We can get you connected with people that would also like to use your language of choice (especially if it is Haskell or Rust). There are people at the lab that use R, and there are people who are interested in pushing things further with Julia.
Anaconda
We will start by using Anaconda, a distribution of Python including a package manager with many of the packages commonly used in data science, and a way to manage programming environments. While not the only way to get started with Python, this is one of the most common approaches. Many collaborators at ORNL will be familiar with Anaconda, and it is an easy way to quickly get people on the same page when setting up their compute environments.
Installation
As of Fall 2020, the Anaconda is distributing Python 3.8. Don’t worry if you
find that you need to use a different version of Python. Anaconda can help you
manage multiple versions of Python within conda environments. Just don’t use
Python 2. It is no longer supported by the Python Foundation, the governing
body of Python.
Side Note:
For much of this book we are assuming that you are using a Unix like operating system (Linux, MacOS, BSD). If you are using Windows, please let us know! We can help you sort out some potential issues you may have. For much of the computing at ORNL, particularly when it comes to the supercomputers, Linux is the default. We do not demand that you use a Unix like OS, but you may have to do some extra leg work.
Graphical Installer
For a graphical installer of Python, follow the download instructions here.
Command Line Installation
If you prefer to work on the command line, you can find various versions of bash install scripts in the Anaconda archive. Make sure that you grab the appropriate 64 bit installer for you operating system in the archive, then download it using wget:
wget https://repo.anaconda.com/archive/<Filename>
where <Filename> is the name of the bash script found in the archive. For
example, if you are on a 64 bit Linux system, use
wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
Once you have that install script, follow the steps outlined after running the installer:
bash <Filename>
Verifying our Installation
Once you have installed Anaconda, let’s check to see that everything is working well. Let’s start by checking where Python is installed:
which python
This will give you a path to where Python is installed. For example, my Python is installed in the following path:
which python
>>> /home/yngtodd/.local/opt/anaconda3/bin/python
We will discuss paths and the Linux filesystem a bit later on. For now, Let’s make sure
that the path you get from which python includes anaconda3/bin/python. If instead you see
/usr/bin/python, then we need to do some debugging as you are using what is known as
system Python instead of Anaconda.
Side Note:
You may wonder whatwhichis. This is a Unix program that is installed in Unix-like operating systems by default. It tells you the path to where any program you run on the command line lives. Knowing more about the command line environment will be useful for us, but we need to get up and running with Python first! If you are curious and want to look further into this, tryman whichto see the manual page forwhich(manis another default Unix program). What happens if you runwhich which?
Resources
- Corey Schafer’s YouTube video on installing Anaconda
- Anaconda Docs
Visualization
Data visualization plays an important role in scientific computing. It is often used in the exploratory data analysis phase at the beginning of a project, where we are trying to build some intuition about our data. It then often steers our experiments as we visualize the intermediate results of our models and experiments. and it is almost always included when we present our results in papers.
Matplotlib
Matplotlib is one of the most mature visualization libraries in Python. It allows us to quickly create figures when we are first exploring our data and models, and allows us to have a lot of control over our final figures for publications.
Like many mature software projects, it can be a bit daunting to work with at first. There are a couple ways to approach things with Matplotlib, through what is known as the state-machine interface of matplotlib.pyplot and the object oriented approach. Depending on our needs, we might prefer one over the other. We will take a look at both of these approaches.
Key Components of a Figure
There are several components of a Matplotlib figure. Understanding how each of these fit together will give us better control over our visualizations. This is important when we want to present our work in papers, but it will also help us debug things when the default settings for figures don’t quite come out right.
Figure
This is the entire figure object. It keeps track of all the figure’s Axes, legends, titles, and the canvas object.
import matplotlib.pyplot as plt
fig = plt.figure()
fig.suptitle('Empty Figure Without Axes')
plt.show()
Axes
Axes are an important part of Matplotlib’s interface. These are what
you would consider the “plot” of your figure, the area in the image
that contains your data. A figure can have many Axes, but each Axes
can only have one Figure. Data limits for the figure can be controlled
through Axes with axes.Axes.set_xlim() and axes.Axes.set_ylim(). Axes
also hold titles and labels for each for each axis. Axes contain either
two or three Axis objects.
Axis
An Axis is acts as a scale delimeter for the Axes. They set the limits
of a figure and control the ticks of a plot.
Creating Figures
While we will take a closer look at this over the next sections of this chapter, there are a couple of things you want to keep in mind when working with Matplotlib.
Input Data
Matplotlib recommends using Numpy arrays as input types for figures. You can often get away with using Python lists and Pandas dataframe objects, but you might encounter some rough edges here and there when using those object types.
Two Iterfaces
As mentioned above, there are two main interfaces for Matplotlib, the state-machine interface and the object-oriented interface. In the next section, we will cover each of these approaches and talk about when you would want to use each.
Matplotlib’s State-Machine Approach
Matplotlib’s matplotlib.pyplot module is designed to feel like MATLAB.
Rather than explicitly creating figure objects, the pyplot module
maintains state as soon as it is imported. If you come from a more
object-oriented background, this may seem like a bit of magic. It can be
a bit difficult to know what Matplotlib is doing for you in the background,
but it does allow you to get up and running with fewer lines of code.
Let’s take a look of a simple example, plotting a single curve:
import matplotlib.pyplot as plt # immediately plt is keeping track of state
# first 10 squares
squares = [x**2 for x in range(11)]
plt.plot(squares)
plt.show()
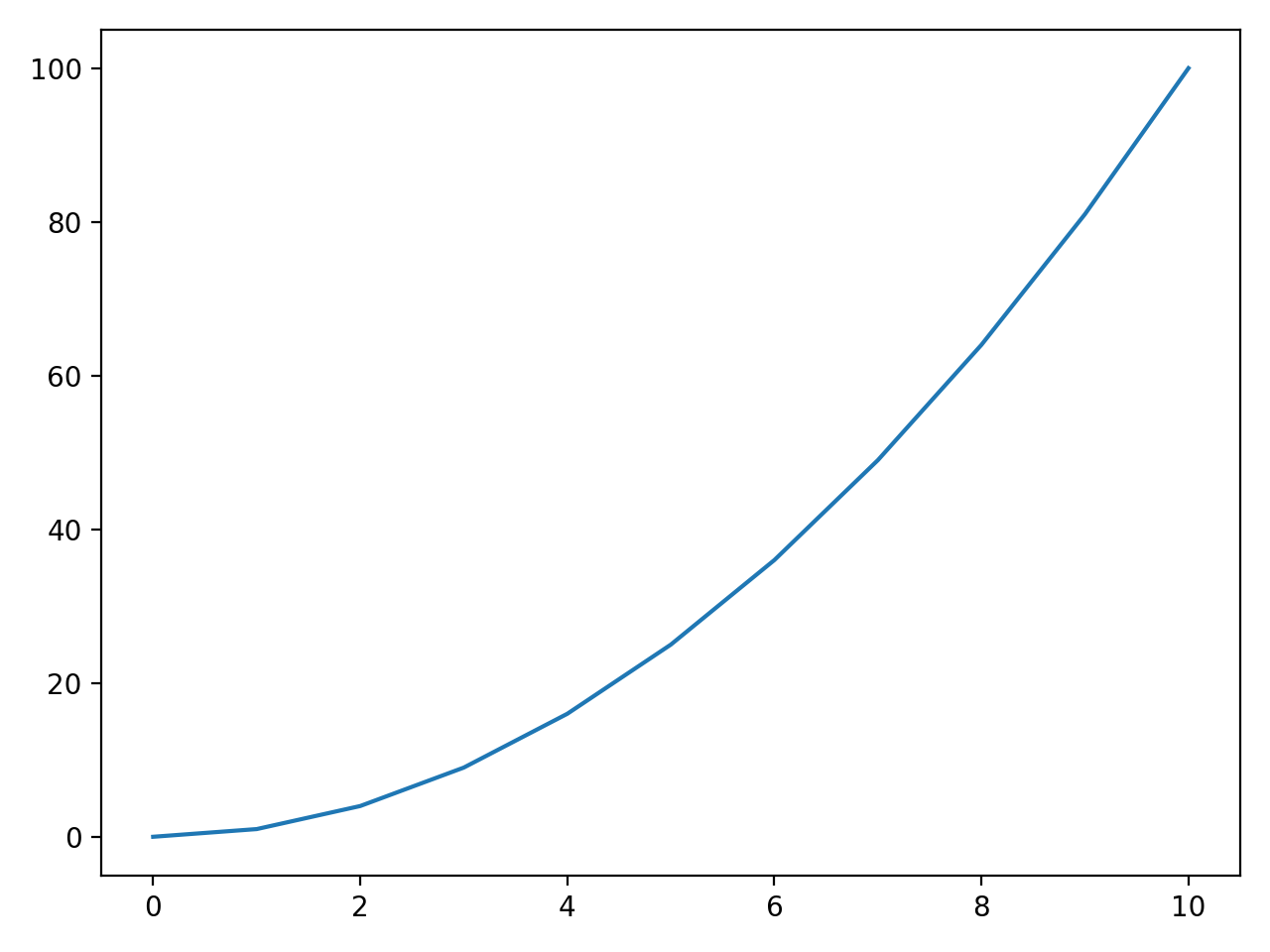
This is about as simple as a Matplotlib figure can get. Given x,
a Python list of the first 10 squares, Matplotlib gives us a line
plot. The pyplot module is inferring a lot here. Notice that we did
not specify our x and y axes. We didn’t even tell it Matplotlib that
we were looking to plot a curve here!
Also note that we never instantiated an object from the pyplot module.
Instead, we are calling the module directly. First, we feed our data
into plt.plt(x), then we call plt.show() to render our figure. If we
were to call plt.show() again without passing the data back into
plt.plot(), Matplotlib will not render the figure a second time. That
is because Matploglib clears the state of our plot as soon as we call
show`.
Adding some Details
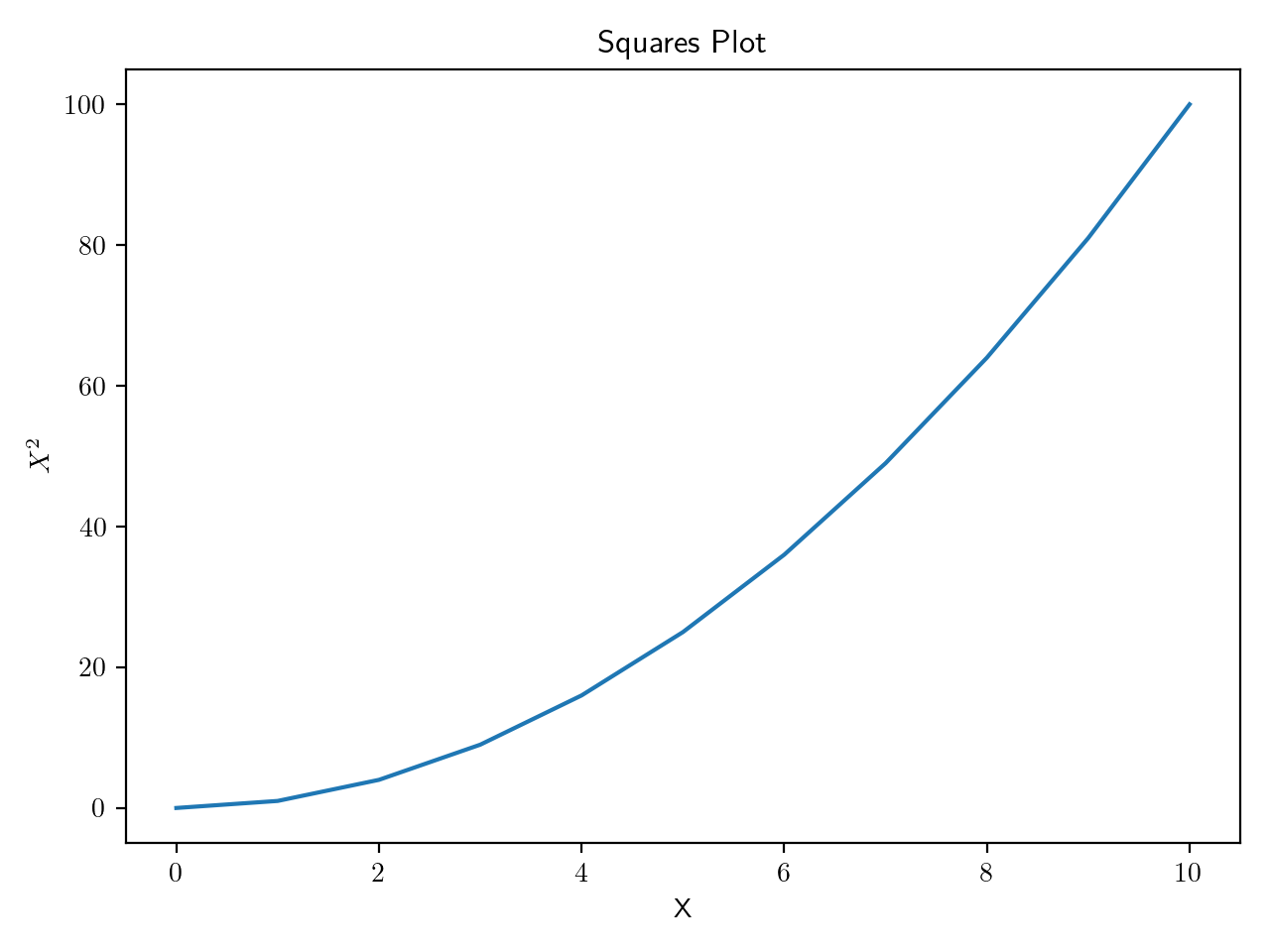
While pyplot can infer a lot of the details for us, we will need to handle axis labels and titles ourselves.
plt.plot(squares)
plt.title('Squares Plot')
plt.ylabel(r'$X^{2}$')
plt.xlabel('X')
plt.show()